The Ubidy platform was built to help our employer partners hire the best candidates, at the right time, and at the best cost. This can be a challenging journey but getting the first step right is the most important. Recently Ubidy had an experience with its AI engine that opened its eyes to the incredible power of LLMs that we share here.
But let’s start from the beginning first.
After a CV has entered the recruitment pipeline, the process starts by qualifying a candidate. This involves the assessment of the CV against the job description. To further assist our employers in selecting the best CVs from those already qualified and submitted candidates, we recently introduced our own AI Engine (Large Language Model (LLM)-based) to the platform earlier this year. This AI Engine assesses the CV against the specific Job Description criteria and provides a graded analysis report on the skill match between the two documents.
When we first launched our AI Engine, our priority was to ensure it delivered quality and accurate assessments. To achieve this, we developed quality testing pipelines for our LLM AI skill match reports. During these routine checks, one of the results flagged by our pipeline caught our attention and made us realize the incredible power contained in our LLM. The AI system had leveraged information not contained in the CV to draw a conclusion as to whether a candidate had the skills required by the job description or not. But the question was, was it correct?
Was our LLM-AI Engine hallucinating?
Ubidy’s AI CV skill matching tool was the result of a year’s work and careful considerations. It was built to avoid the issues of many other candidate assessment tools plagued with bias and fairness issues and so it just focuses on the criteria listed in the job description. Below is a screenshot of a part of the LLM’s analysis report for the job in question:
For the job in question, the JD required that the successful candidate have SAP skills. However, when we double-checked the CV, the word “SAP” was not mentioned anywhere. Naturally, our first conclusion was that our AI engine had made an error. This incident initially caused significant concern as we feared we might need to replace the LLM and start from scratch again. We had invested a considerable amount of effort and time into integrating the LLM with our platform and testing various prompts and their outputs before making it live for our clients.
Our AI team started investigating this issue. What made this investigation effective and straightforward was that Ubidy had built its AI tool to provide reasons for its decisions. This allowed us to understand and easily validate why the LLM had responded yes or no to a specific criteria. In this case, the explanation was truly eye opening.
It stated that although the skill is not explicitly mentioned in the CV, it is clear that the candidate would have experience with SAP due to his having performed audits and reviews of financial and IT related controls. In addition, the candidate’s experience in coordinating with external auditors for annual SOX audit and preparing audit working papers for Board Audit Committee meetings suggest that the candidate has knowledge of SAP frameworks. In addition, it seems that the LLM knew, from the publicly available information, that at one of the employers the candidate worked for, in the division the person worked, it was public knowledge that they used SAP. When these results were fact checked, amazingly they turned out to be true.
So how did the LLM manage to provide such a powerful result? And what can we learn from this to draw conclusions about the future of AI systems in such applications?
What our LLM did: Data Enrichment
Traditionally when a CV is received by an organization, this (and perhaps a cover letter, a review of the candidate’s social media accounts or recommendation from a recruiter) is typically all a company has to assess a candidate – not any more.
Data enrichment with LLMs offers a profound enhancement to traditional CV screening. By drawing on publicly available information about companies and correlating this with an individual’s tenure, LLMs provide richer insights into professional histories. This approach ensures the augmentation is based on real, verifiable public data, not fictitious information.
However, it is crucial to apply caution in utilizing these insights. LLMs can sometimes generate inaccurate or misleading information, a phenomenon known as hallucination and also not all information that an LLM is trained on is correct. As is done at Ubidy, additional information provided by an LLM requires a careful prompt to elicit the right insights as well as separate human verification (including the source validity) to ensure it is correct, something that we have found in our experience is overwhelmingly the case.
LLM Data Enriched CVs: The New Future?
When we have so little information to use in making a critically important decision as to whether to hire someone or not, it is essential to seek appropriate help from wherever one can find it. The screening of a candidate is often a fast process, so helping candidates put their best foot forward with personal facts relevant to a job that they may not be aware of, helps all parties.
Ubidy can see a future in which all companies leverage their own LLMs with their own proprietary, internal prompts for each job that then provide additional information about a candidate’s professional history by analyzing additional information that the LLM was trained on.
Embracing LLMs for data enrichment can significantly improve our understanding of professional profiles, provided we navigate their limitations with care.

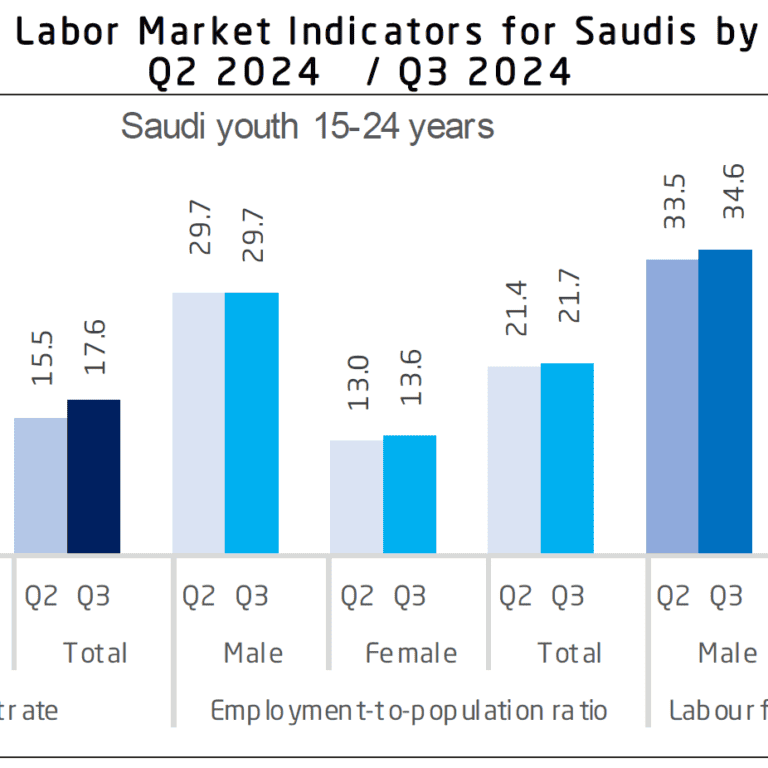
What Saudi Arabia’s Latest Labor Market Data Means for the Recruitment Industry
The third quarter of 2024 labour market statistics for Saudi Arabia offer a rich landscape of opportunities for recruitment agencies to support Saudi Arabia on its aspirational Vision2030 goals. With...
Read More
Singapore’s Latest Labour Market Analysis Compared to Australia
Recently Ubidy had the pleasure of being invited to join a trade mission to Singapore and Malaysia and as a part of this trip, we noticed some fascinating aspects of...
Read More